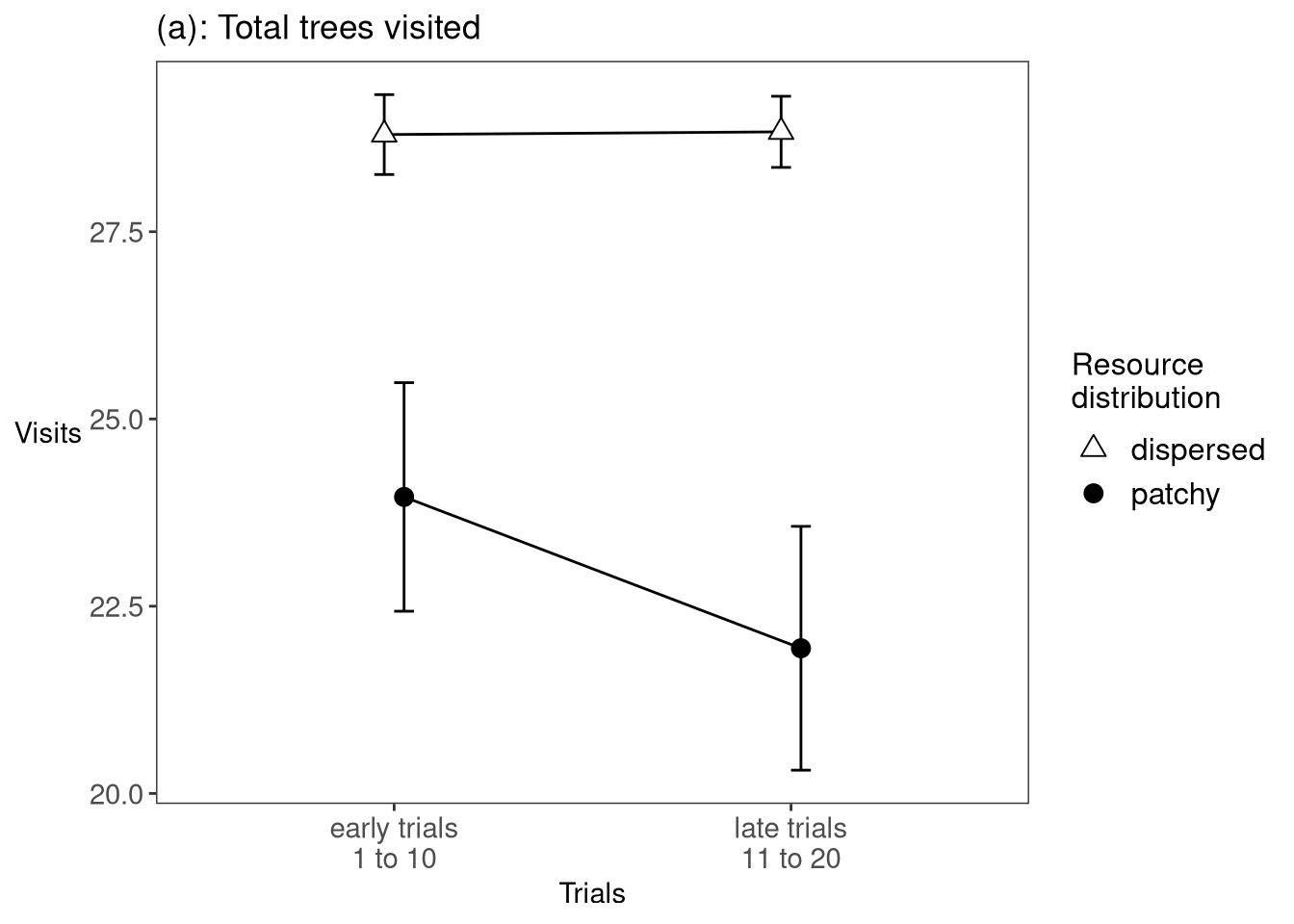
This number is how many trees they looked at overall to get the fourteen out of fifteen fruit - high numbers represent worse performance.
E2 Ntrees: Prepare the data
Read the data in and pre-process it.
Show the code
e2 <-readRDS("002-00-e2-data.RDS")# remove things from the raw data to make it # suitable for this particular analysis# remove samples that did not look at a treee2 <- e2 %>%filter(fl>0)# remove the second (and any subsequent) *consecutive* duplicatese2 <- e2 %>%group_by(ff, pp, rr, tb) %>%filter(is.na(tl !=lag(tl)) | tl !=lag(tl)) %>%ungroup()# remove trials where they failed to get 14 fruite2 <- e2 %>%group_by(ff, pp, rr, tb) %>%mutate(max_fr =max(fr)) %>%ungroup() %>%filter(max_fr==14)# average over tree-visits to get counts for each trialntr.counts <- e2 %>%select(ff, pp, rr, st, tb, tl) %>%group_by(ff, pp, rr, st, tb) %>%summarise(ntrees=n()) %>%ungroup() %>%mutate(ff=as_factor(ff), pp=as_factor(pp), rr=as_factor(rr), st=as_factor(st))# average over trials to get mean count for each stagentr <- ntr.counts %>%group_by(ff, pp, rr, st) %>%summarise(mean_ntrees_per_stage=mean(ntrees)) %>%ungroup()saveRDS(ntr, "e2_ntrees_plot_data.rds")